A B2B AI-native pre-seed
WIP! With graphs and charts soon :)
The setup
MLE talent today is scarce. Full stack devs are regularly outcompeted by new grads when this field’s most important engineering tenets are less than 5 years old.
Sequoia recently talked about the 5% rule - where any industry is ripe for disruption with an AI native tool if an AI agent outperforms the bottom 5% of white collar workers. Building with AI is a field that nobody has more than 5 years of experience with, especially applied AI transformer based use cases which also require an open mind every day to keep up with new changes.
I’d love to write 1-2M checks for a group of reasonably talented MLEs with pedigrees from strong hiring networks (old co-workers at rocketship cos, or strong university peer cohort networks), who also embody FDE customer discovery as a mantra.
If MLE talent today is scarce, and model improvements agnostically beat employee performance in white collar fields, then the enterprise adoption is just a matter of:
- Engineering to create enterprise safe environments - whether it be on prem or locally hosted models
- Engineering to specialize and distill models such that they can be engineered to be cost effective for enterprise use cases
- RL tooling to get to 100% on custom benchmarks on custom enterprise workflows - or some generalizable pipeline to onboard enterprise ontology into model context layers appropriately
For the third time, a technology infrastructure shift has occurred such that the possibilities of what can be made with PMF dwarfs the talent out there - talent is scarcer than opportunities.
Conditions for picking an industry to build AI-native solutions in
Given the setup, what makes an industry ripe for building now?
- Legacy industry has interfaces that are available for agents to interact
- UI-level browser automation is possible, but rarely alone can get a white collar task to 100% accuracy or needed benchmark metrics for adoption
- The presence of APIs with strongly indexable documentation along with enough reasonably long horizon complex tasks that remain at the edge of benchmarks. We want tasks to be not so easy as to be completed with agnostic increases in OAI agent mode capabilities, but not so hard such that entire new model architectures must be built for some tool calls.
- Proper evals to benchmark if the 5% rule is breached - measuring agent v human productivity deterministically
- Sometimes evals are easy - like how code verification is often just whether it compiles or not. Many times, they require curation of tasks similar to how many RL environments are today with clear assumptions and complex programatic verification.
- Is there a path to adoption with gradual human in the loop? Assume that all initial sales processes here look like FDE services engagements gradually becoming productized over time.
- Orgs are open to spend - this isn’t just ephemeral spend
- Eg while there are reports floating around that 90% of GenAI pilots fail, 66% of AI pilots from external vendors actually have measurable ROI, suggesting that there are a proliferation of executives at legacy enterprises mandating top down AI buildouts for non-AI native teams.
- Target high value use cases where you already see the most tech forward companies trying to build internal solutions. Coinbase’s KYC operations, or Goldman’s legal contract automation (or general back office automation) efforts are cases here through the grapevine.
- More hints are legacy UIPath and Cognizant workflows that are often brittle owing to task complexity - these are often $20M spend categories in large enterprises that they’re willing to pilot lower cost/latency solutions.
- You have cracked MLEs, a pedigree/network that allows you to forward talent, or a large online presence that allows you to use cloud/vc brand to hire well
- Bonus points if you’re charismatic and know the fine line between using clout for hiring and letting clout dominate your hedonistic tendencies
- We used to mandate option pools to attract talent but equally common as of late is folks raising overvalued seeds and using excess equity to give founding engineers 2-5%
In July I posted about how fdes and full stack 1st startup hires are getting harder to hire, perhaps with antiquated compensation models still assuming roles were siloed, resulting in services like paraform absolutely ripping.
In vc land, we often mandate option pools (10-14%) to allow founders to attract talent but equally common as of late is folks raising overvalued seeds and using excess equity to give founding engineers 2-5% which are incredibly large as compared to before.
Seen a few of my angel check startups use this as of late to bring their quant researcher/10x eng friends onboard. Perhaps a very good use of the frothy markets now to get excess equity for top talent to work for you.
Bonus Addendum:
Teams also need connections to hyper spender enterprises to engage in services-based engagements.
- While VCs often over-index on pedigree from, work experience at top startups or universities, its undeniable that pedigreed networks will likely get you in front of coinbases/cursors/OAIs of the world.
- Hyper spenders in AI apps follow power law - that is, the biggest applied AI inference users right now are Cognition, Cursor, Reflection, code generation companies, Perplexity, and Suno. Fireworks has 70% customer concentration on Cursor alone for example.
- A more extreme example is Mercor’s incredible customer concentration on two key players - Meta and OAI - of which one of them pays $6M a week
- Is there a play to sell to smaller players in the hopes that they grow up to become Cursors in their respective markets? Maybe, but that’s risk that you have to price in at the pre-seed stage.
- There are ways to develop these wedges and vendor relationships by selling some other over-commoditized service extremely well or working on mission critical problems with near-zero or slightly negative margins.
Skip the accelerator, live with the customer
The accelerator tax ranges from 5-10% equity in a company and I liken it closer to a pre-seed. It is a reason why YC companies tend to raise at inflated valuations nowadays - to offset the tax and for YC to pass dilution off to the seed investor. Increasingly - YC competes with the pre-seed investor at the founder bet level - and often wins on community and brand.
If you believed in my 4 conditions for picking an industry to build AI apps in, then you’ll notice that YC is great for two things - warm intros to hyperspender enterprises and a somewhat elevated hiring network boost.
These are things attainable without YC and other accelerators. Possessing these things gives credence to skip the accelerator. Attaining these things also doesn’t require accelerator networks either. To quote their adage - you can just do things and its important to benchmark YC’s value beyond the community cult.
Maturing Markets
If code and (debatably) search were the first mature markets to enterprise, then what are the next mature markets that are ripe for agentic deployment?
Recent rumblings from labs and efforts with those close to labs (Mercor’s AI productivity index) indicate that it is white collar tasks like those in finance, healthcare, and law, which are directly mentioned on new foundation model benchmark releases now.
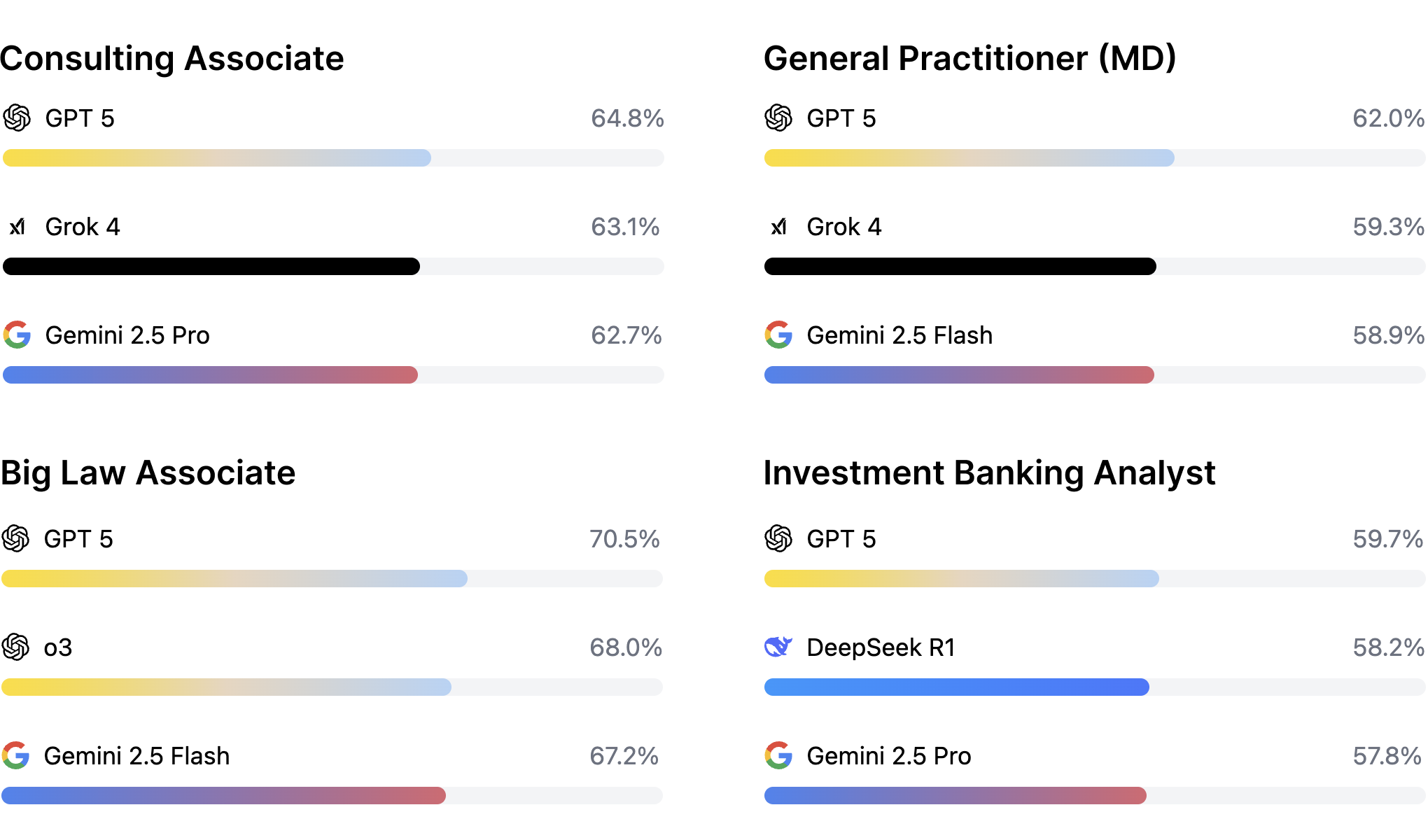
Source: Mercor
In OAI and other labs’ quest to move into the app layer, they’ve attempted to setup the groundwork for easing app layer expansion. An example is the grove startup program, where they’ll likely incubate teams with domain expertise in areas that generalist foundation models don’t currently do well, then acquihire as they give internal specialist model access/perks. A second principles thinker may also be more convinced from seeing OAI’s basic RLaaS services like finetuning over API as well as bet on general enterprise adoption via consulting.
Applied Compute, Thinking Machines, as well as open source developments in Prime Intellect and Nous Research lend more credence to the idea that agent customization and reasoning level unlocks from post-training techniques will be democratized.
The problem of having a model pass a white collar task on a benchmark and the problem of having that model perform that task is a huge delta. This is a strong reason why vertical specific FDE MLE startups can still exist in a post-AGI world as well.
What are white collar domains with maturing markets that are interesting to look at? Here are some conditions:
- Domains that don’t have copious amounts of pre-training data (in all modalities) available on the consumer internet
- This is a strong reason why coding was such a ripe market initially - pre-training captured much of the data needed, and no particular complicated tool calling capabilities were needed beyond text interaction with IDEs
- Domains that require highly skilled expertise whose retraceability is often locked up in enterprise workflows
- Domains that aren’t a strong subject of net new data creation by companies like Mercor and in-house data teams at Mag 7 labs, either because of lack of focus or inability to source relevant domain experts effectively
- Domains whose work requires a strong blend of reasoning and tool calls to model effectively and where knowledge workers are highly paid
As you can see, this actually quite a few markets today, and will be compound when physical/world models extend tool use capability into the real world with robotics!