World
State of Data (Jan 2026)

The "Mechanical Turk," the 18th century version of a black box machine for a multi-turn reasoning task (chess)
Industrial Historians should be salivating at what is going on in data markets today. We've built the bona fide combustion engine and now
Production of white collar knowledge work is undergoing a radical, Victorian era-like industrial shift. The TAM is all of human labor, but its spread out across several subcategories developing within human data where newer players can outcompete generalized incumbents. And even though Mercor offers acqui-hires to many of them, private capital markets, though frothy, are nothing like those in the early 20th century. Even if data titans wanted to employ Standard Oil-like acquisition plays to vertically monopolize, macro trends are driving the supply chain to be split.
Data contracts are much more easy to eat away at than they were 2 years ago. The market is much more mature and knowledge asymmetries fade as more miners enter the data markets. Throughout this entire year, I'll explore the notion that, in absence of being able to innovate at the continual learning paradigm level, we need to dramatically redefine how we collect data and realistically transform it into evals to match the new SOTA models and deployment practices.
The Industrial Age and the Information Age
In the early 18th century, as the most optimistic and foolhardy industrialists of the early waves of the industrial revolution posited the limits of industrial innovations they could imagine, they landed on machines that, through no obvious mechanism, could produce miraculous outcomes. Such were the misguided attempts at creating machines that "spoke" to emulate speech in Viennese courts, the machines that sought to emulate human reasoning at some scale by some French inventors, and machines that outcompeted humans on reasoning tasks, such as the infamous mechanical turk made to impress Empress Maria Theresa in the image above.
Evidently, there were a few technological breakthroughs that needed to happen before we could even get to a point of delegating high level reasoning to machines. Today, we have the best chances ever at realizing what the inventors of the mechanical turk had in their wildest dreams. And increasingly, we deploy systems that abstract away low level reasoning, spawning modern age white collar luddites and over-investment bubbles, but who ultimately contribute to massive improvements to white collar economies of scale.
Coal, iron, sulfur, lead, and a mishmash of other physical materials powered the physical labor revolution of the Victorian industrial age. Data, alone in its many modalities and white collar representations, will power the white collar labor revolution of the Information age. Soon, as even general purpose robotics mature, it might power a blue collar labor revolution as well, abstracting away low level reasoning at all levels of the economy.
We always face an issue between balancing pattern-matching on our most applicable historical examples and generalizing to new situations with considerations to new technologies. In this case, let's examine the things that are most probably generalizable from the last economic revolution, and the things that are not:
What Industrial History Actually Generalizes
- Human power dynamics towards the resources that most directly translate to throughput:
- Just as how England and the rest of the industrializing European powers resorted to economic, and finally physical colonization, in order to extract raw materials such as rubber, oil, and silk/dyes/fabrics in order to fuel their continued expansion, I predict we'll see similar dynamics in data acquisition
- Already, we see a sort of "data imperialism" where RL env companies in the US today buy and arbitrage real world datasets created by those in other countries who have little to no AI talent - I'll coin the term "mimetic imperialism" to describe this.
- Low level labor examples, data, and innovations from 3rd world countries will power the AI information economies of the new age, who have a combination of MLE talent, capital markets, and amenable talent policy proliferation
- Human nature and governments haven't changed too much (only the outlawing of direct physical colonization), so I don't see this as being markedly different.
- Luddites (and their unavoidable proliferation)
- Those who rallied around Ludd in England will forever be immortalized for coining this term. Always, as there must be owing to the mismatch between human culture, the governance systems we create, and technological advancement by private individuals, there will be pockets of individuals who can't ever match qualifications with new jobs
- I've thought about this a lot. This is reasonable and unavoidable. This is a negative externality of piles of other governmental systems whose positive externalities are necessary to technological innovation, so don't be elitist about this.
- Some initiatives against data center rollout, nuclear rollout, as well as generally uneducated individuals on AI are the biggest proponents of this category as of Dec 2025
- Many more spinning looms will be destroyed and decried as useless "AI slop" by the artisans of today
- Policy Innovation and Technology go hand in hand
- The distribution of wealth and production are large determinants of the best governance structure a society should have
- A society dominated by landowners will extract more tax revenues from land-based or per capita-based taxation, while a society with a larger distribution of wealth and a strong white collar middle class can extract high and more fair revenues from proportional and graduated taxation
- This is a common theme espoused by the struggles by original Bolsheviks to transform Russia from an agrarian society into an industrialized one such that communal ownership made more sense - wealth and knowledge were still too concentrated in few individuals from previous systems
- We need policy innovation to match wealth accumulation and balance minimum standard of living expectations to guard against societal unrest
- People will generally find the roles where they produce the most economic value, given that they have the prerequisite education
- Education, in a techno-laissez-faire view, is resultantly the most important public institution to keep cutting edge
- The distribution of wealth and production are large determinants of the best governance structure a society should have
What's different today:
- The data associated with the labor that created that data is generally uniquely valuable to the labor that created that data; resources are not immediately completely fungible
- Even if we do imperialize datasets from abroad (eg Brazil, South Africa, etc.), the models and evals trained on that data will, of course, best match to those users, especially in white collar settings
- A direct example is training accounting models on IFRS (used in the majority of the world) versus the US's GAAP methods, but at some point differences like these will probably largely be treated as context management problems rather than training problems
- We can reasonably expect China to develop as a proto-Meiji era Japan in this regard, copying the methods of industrialization from Western powers but ultimately relying on domestic resources to industrialize as best as possible until natural limitations require it to look outwards
- This is in stark comparison to natural resources like coal, whose composition doesn't really change where its sourced. Evals today need to be dynamic and constantly changing every week, with real world data pipelines that are generally as diverse as possible. This is the short term focus of my current day work.
- Evals themselves will become a sort of "finished good" in the human data supply chain with some elements of non-fungibility (they will be best used in the cultural contexts, and by extension geographies, wherever created)
- Even if we do imperialize datasets from abroad (eg Brazil, South Africa, etc.), the models and evals trained on that data will, of course, best match to those users, especially in white collar settings
- Private capital markets availability
- In 17th/18th century Europe, public markets mechanisms where HNIs could finance and subsequently capture a portion of high risk ventures was an extremely novel concept. Such arrangements financed the East Indies Companies voyages (of which few, apart from the British and Dutch East Indies companies, succeeded).
- Today, we regard public markets financing as a given, and regard the proliferation of private markets financing capital (that proliferates in unsophisticated amounts even after copious regulation attempting to deter retail investors from entering the market). We've devised the concept of private markets in order to foment economic opportunities that could only be developed by sophisticated investors without the whims of common retail investors. It is a delicate balance - but one where private markets use this information asymmetry field to increasingly pass off one-sided gains to public markets who are generally too disunited (in absence of government protective regulation) to do anything about it.
- TLDR: as the pools of capital funding mechanisms widen, the payoff horizons of certain technological investments are more feasible. With it exposes surface area for fraud with longer capital lock up cycles, but the general economy feels a sort of overconfidence in over-allocating to private markets (especially early stage), seeing some kind of magical mechanical turk mechanism within it. Regardless of the causes and whether justified, private capital funding mechanisms of all sorts of motivations are abundant, and any sort of driven talent (especially pedigreed) can find ardent backers.
- English is the technological lingua franca
- Resources were commoditizable in the 18th century, coal from the Transvaal and Shanxi was generally the same as coal from England's Home Countries, and we simply needed better native administrators to harness human labor to harvest it
- In model land today, we notice a concept called "token fertility" whereas it costs substantially more tokens to represent words and sentences in different languages than English (due to English overrepresentation).
- It will literally cost less to do English-based training and inference as a result. White collar reasoning data in English is worth its weight in gold - formerly British and American colonial states are particularly mimetically imperialized today for reasoning trace data.
- Upskilling with new inventions is different
- When the spinning loom was invented, its adoption was simply a matter of production and reskilling. When AI tooling came out, its adoption could be viewed the same way
- However, today's information era revolution not only multiplies the productivity of individual workers, but also the number of workers one can deploy, circumventing human labor market constraints
- The labor market is only more competitive today not just because there are more people, but because multiculturalism is abundant and we are generally more talent/education constrained than not
- A new class of infra in every industry is needed for seamless human-agent interaction. How do we discern malevolent agents from benign agents when computer use interaction all looks the same?
Those who forget history are condemned to repeat it.
Lights amongst the Bytes
Public players making more and more AI acquisitions to build specialised capabilities is another light in the tunnel for the glut of companies who've raised venture to become data vendors for 7 companies.
Simply put, these companies have been wading about the deep end for a while hopefully innovating on sophisticated post-training data products while being subsidized by labs via data spend. Hopefully many of them will have used their time well by not giving in too heavily to operations (Mercor) and innovating at the engineering innovation level.
Particularly, as I mentioned in my previous piece, four key infrastructure problems around cutting edge RL, if anybody has built them (with talent dense teams), make them great acquisition targets:

Reward model scaling == automatic reward rubric generation from messy, chaotic, enterprise context and directives
I'll add some context to the above:
- Reward Model Scaling can also be defined as rubric generation and adherence for increasingly complex enterprise tasks.
- Data (for RL envs) increasingly refers to "realistic data," of which the human data companies increasingly compromise on in favor of creating "hard" benchmarks." Though this is for another post, realistic data seems to, increasingly, only be attainable by building real world enterprise data pipelines for observing live white collar work traces.
- Env maintenance and env task creation are QA problems (interaction tooling between the MLE teams and product/sales teams) and human data maximizing problems (synthetic task generation to improve human data generation throughput of scarce domain experts)
Let's look at this obsessive graph I put together a while back.
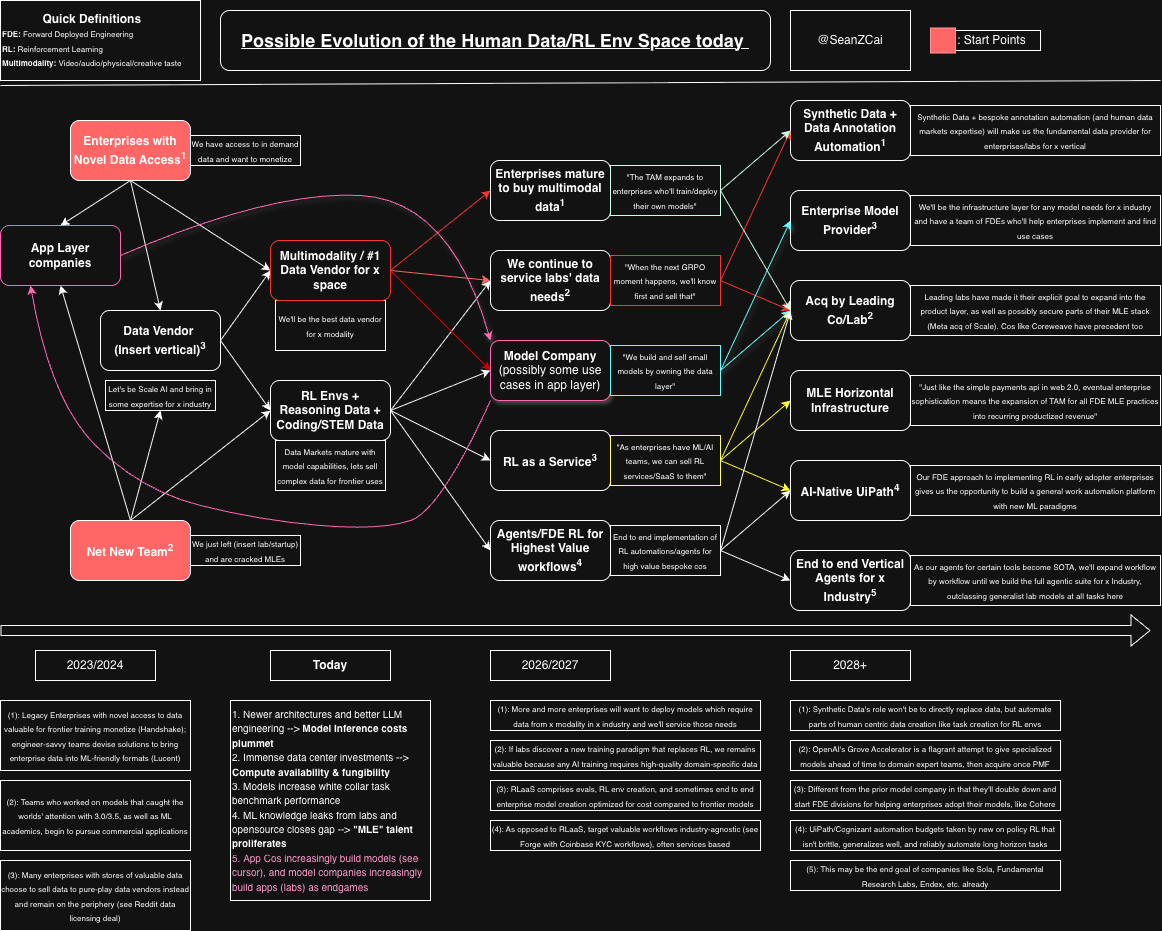
Evolution of RL Data Companies market map
We're now in 2026, and everyone is re-evaluating on where they can win. Its clear that there are multiple categories for multiple winners now - and everyone is being asked which one they are now.
It is quite likely that 2-3 RL environment companies, or post-training research-lite companies, who'll lose RLaaS contracts to the likes of Applied Compute or data contracts to data vendor 2.0 companies like Fleet will be enticed to be bought out. They will likely have built out robust attempts at automated RL env generation engines and subsequent automated reward shaping, and built a battle hardened team of FDEs doing implemenations in sophisticated enterprises like labs as a result.
Some, who've pivoted to RL infra, will be acquired by large incumbents for platform plays like Tinkers' (maybe even Thinking Machines as an acquirer?). This is like Hud - who could be possibly eyed for acquisition by a resurgent Prime Intellect at the lower end and an empire building Post Hog at the higher end. A comparable is Parse's acquisition by Meta in the 2010s.
It is also quite likely, that 2-3 RLaaS companies will be similarly acquired. This will be for a combination of their FDE expertise migrating enterprises with poor data preparedness to RL-capable data ontologies as well as aggregating learnings from enterprise RL deployments. Emphasis on the former, given that I don't expect any to have developed any particularly robust platformized RL solutions on a Tinker level within 6 months. You may see an Osmosis/Veris/Distyl, be prematurely acquired in a bid to build Tinker level competitors.
I preface my next statement with the fact that, although I would consider myself an insider in private markets in this space, I've no insider information on potential acquirers in public markets besides my PE/Quant friends. That being said, the likes of Palantir, Salesforce, Servicenow, and any companies who've internalized FDE as a product and marked it up via their brand name should want the automatic enterprise ontology —> reward rubrics tooling that post-training data vendor startups are building today. This tech exists - but they're being kept under the wraps because somewhat automated curation of high quality post training datasets (and infra) is still a money printer that can only be operated at a small scale for research labs.Some of the compute/inference larger enterprise players (Base10, Fireworks ML) should also be expected to acquire RL env teams, as the product lines are complementary and the expertise, analogous.
I regularly talk to enterprise execs who head applied MLE teams at the likes of Synopsis, Cadence, etc. who regularly express disbelief that any small scale RLaaS or env startup can build something they can't. That they can build infra, scalable data, and reward rubric curators that transform business logic/processes into model actionable formats. I'm here to tell you that they are - and the reason why they're better suited to building those is that they work with a large variety of companies/cultures/data lakes rather than the enterprise applied MLE teams who only work with one. Specifically:
- Reward Model scaling becomes easier when you're exposed to a diverse set of messy business directives and contexts; inherently any automatic reward rubric generator models you build will probably be more robust when your day to day is industry agnostic
- Realistic synthetic data generation for tasks (that is actually diverse, something inherently impossible when all your data is from one company)
- RLHF pairs for translating semantic language and general enterprise observed behaviors, from a variety of motivated and unmotivaed employees, into actionable reward signals
- The diversity of companies they see and work with - like RLaaS companies - such that they're able to tell me stats like "40% of all long horizon enterprise model deployments people struggle with and consider sophisticated post training like RL are actually customer service support chatbots" so we should build generalizable post-training infra for that use case
- The simple fact that they probably work in a more innovative organization, with much better monetary incentives to innovate, than any head of applied ML at a 250+ employee company
The best heads of your next FDE department, by this logic, are also heading the RLaaS and post-training data vendor companies. Even if they sell data, they will have to do things like train models on their own data to sell to labs, in order to inspire confidence. Some of my readers might laugh and say I have "rosy-tinted glasses" here, but I'd counter that people get sophisticated fast, as I'll explain later.
Localized N-1 Intelligence
The earliest days of N-1 intelligence that could run locally on consumer hardware reasonably was Deepseek's r1 model at around parameter size of 7b. I often used this during flights via Ollama in order to find leisurely answers to rote questions best answered in large pre-training data sets, but observed the earliest versions of "hard-coded" chain of thought reasoning chains, which were necessary for small models to reach economically useful states.
Today, as of Dec 2025, small models are being scaled by architectures and "deep-tech" techniques to such a successful degree (shoutout to my friend and portco Eddie from Deepgrove) that they match near frontier models on performance (GPT 4.1). Some frontier labs have even resigned themselves to making their frontier models N-1 (slightly lower benchmark performance for massively decreased costs, see Gemini 3). This aforementioned tailwind, and the latter observation, simply create certainty that models are good enough for incredibly large enterprise and consumer app layer TAMs today.
The evident 2nd degree layer effect is cost related. As I presented in this econ 101 chart from a world of serviceable domains, as we roughly equate model actions to replacing service-based low level reasoning workflows today, we can effectively push the cost of some services to below minimum wage for human workers. As a result, so many more services for our customers become cost-positive, expanding TAMs for both existing players and opportunities for new entrants.
Non-evident 2nd and 3rd layer effects lie in the stratosphere. Which is to say, simply, that there are an inordinate amount of problems with deploying localized N-1 intelligence at scale, as well as deciding how to interface between local model deployment and large scale model orchestration. The incentive mechanisms behind deploying small models in AI app layer architectures and workflows today is hindered by private capital interests and inertia, but will soon proliferate by creating long-term economy of scale advantages. Already, some of your favorite logos today with extensive compute usage, sophisticated MLE teams, and lots of RL see investing in their own bare metal as a non-negotiable strategy.
N-1 models will largely be opensourced, distributed, or distilled/finetuned by enterprises in house. Frontier models will probably largely remain API businesses, but used as either swiss army knives or sparsely used high level planning models. This tracks with how RL env businesses are developing today - aware that the demand for expert-produced data in its current forms is waning and attempting pivots to RLaaS tooling for enterprises today seeking a new class of midrange models and datasets.
Vendor Diversification will persist
On labs - vendors won't be consolidated as long as people continue to pursue verticalization. We are in a world where this sort of data distortion continues to exist because players that develop great relationships with labs on a first initial set of data, then quality drops off, and people start failing to scale quality with quantity. I don't blame them for this - this naturally has to happen because these startups have growth incentives from taking equity capital and whose founders are naturally empire builders as a result.
In this world - how does it not make sense that a lab will prefer to work with multiple vendors? If we see quality not scale too linearly with quantity, and this is an enduring feature because of capital markets growth incentives, then labs will prefer to keep data markets incredibly fragmented. Free markets competition is good, however, as these conditions allow for human barons to be cracked at by multiple smaller vendors, and for small categories within human data and AI to become large TAMs. They drive the innovation and inherent unbundling of human data markets, which naturally curbs empire building behavior.
Naturally, labs will extend their tendrils down the human data stack in attempt to see what they can do well, because of how valuable this new age commodity is. They will spin up human data teams who attempt to source their own data, or clean raw datasets at scale into sophisticated post training data formats. They will soon find that this is not something they're good at, nor have the incentive structures of startups to do, so will retract to the peripheries of verticalization. Human data teams who work in big tech can never have the same financial incentives as a founder anyhow.
An interesting thing is happening in data buying practices for the most advanced data domains today. We want less, more high quality, data, as the frontier of models gets pushed outwards. Ironically, that we expect a much smaller and higher subset of quality of data to drive the majority of model improvements. This is happening in every single data modality, with text/reasoning based being the most advanced. Perhaps when we create architectures that parse interweaved data well, we'll have an "omni-modality," but until then, multimodal data is going the same way as text data.
If the amount and types of data today that is valuable in a way such that data can get bought at venture scale, than it is unreasonable to expect vertically integrated players like Surge and Mercor to dominate the entire market. Let me illustrate the various markets at play:
Text-based data markets serve as our first empirical view of how data markets play out:
We were impatient with the corpus of text-based data in sparse domains, so we asked and paid companies like Mercor to produce more of it with their expert networks in 2024.
We were impatient with the amount of purpose-built RL gyms to simulate real processes and environments, so we asked the same data vendor companies to make those in 2025.
Everybody knew RL to be a prohibitively data hungry algorithm for a long time - but once we developed the proper economic incentives for data gathering, we could scale it. But data markets also existed at different vertical levels - pre-training datasets, post-training gyms, and every constitutent part of that which could be shipped via parts and re-assemebled.
Notwithstanding sophistication of data products, different verticals can also emerge:
And as we climbed models to high school graduate levels, just as we specialize humans in post-secondary education, we wanted to specialize models as well.
Although much of it was driven by the domain-specific directive spend by AI labs in the heat of the moment, domain experts together with MLEs capitalized and became piranhas in data spend budgets to the larger generalized data vendors.
See financial data (Isidor); medical data (Centaur); mathematical data (Hillclimb)
And who said only frontier datasets are valuable? If your aim is to do model training for N-1 models, than the Micro1 approach is perfect:
The performance degradation between N-1 models and frontier models as of Jan 2026 is such that app layer companies prefer to continue using SOTA. Increasingly, folks are training smaller, more domain specific models, that don't need particularly out of distribution frontier datasets.
If you imagine a XY axis where X represents cost and Y is performance, as we hillclimb, the surface area of possible selections possibly grow. We can mix and match cost & performance, especially as it pertains to diversifying domains, more freely as applied MLE teams. But for this increased surface area of pre-trained models on different cost-bases, we'll need complementary data products for post-training.
Perhaps these datasets are private, abundant, but not open source. In this world, than wouldn't Micro1's approach of offering N-1 datasets for N-1 models work by virtue of the large TAM created by self-hosted model training disseminating in enterprises?
And we can expect multimodal data, especially of that attributed with voice and video, to go the same way:
Text models work with high-level, human-curated symbols (words) that already represent abstractions of meaning while other modalities must learn these abstractions from low-level, raw sensory data (pixels and waveforms), which requires processing much larger datasets to discern meaningful patterns from noise.
Voice models must not only capture transcription, but also nuances like intonation, emotion, accent, and speaker identity (see duplex speech models). Similarly, video models must understand spatial relationships across frames in relation to audio as well. 3-dimensional data structures, augmented with even more dimensionalities to create attention for.
We're not exactly sure of our dimension reduction algorithms to scale these multimodal modals, so we surely need to capture all of the features first in a data rich format to find that out. Luckily, we're off to a good start in 2026 with increasing research into hyper connections for scaling residual connections and increased focus on model architectures that can do efficient unified processing across modalities with interweaved data (interaction-aware LoRA).
With 4 different dimensional categories, you could pick a basket of words - multi-turn financial data for frontier labs - and build and raise for a startup, given you have pedigree and some argument as to how this wedge allows you to win the rest of your category in one of these 4 dimensions.
In 2026, voice and video models address "hyper-connections"—the complex, high-density interdependencies within multimodal data—through a combination of architectural innovations and infrastructure upgrades designed to manage massive data intensity.
And smaller players continuously eat away at the lunch of larger players. Especially in the era where, as mentioned before, less, higher quality data pushes the most frontier of models:
Isidor, for example, has stolen the entire budget in the data preference stack at labs I'm familiar with for their niche.
Its not only that you'd want similar MLE expertise in your data vendors to gain more trust, but also data lineage and confidence that the way they're curating datasets is tied to realism. Especially in light of some leakage of some egregious data curation practices at top data vendors.
Data isn't a vendor lock in business in the way SaaS is. If the first pick vendor can't fulfill the order, it'll just go to the 2nd one. Inspiring confidence, often by being vertical specific, to get on top of that preference stack, then repeating this across different verticals, stages of processed data (pre and post), and increasingly across modality, while make it hard to be a general-purpose vendor, especially if everyone knows your SPLs have only been on the job for 2 months.
Though I've extensively described how the RL env and data markets will change and expand, there will be room for the current players to exist in their current form. There will always be megacap players building frontier private models. They will always need a smaller, highly specific subset of labor on demand to source well cleaned post-training datasets and tooling from. The further these domains and data products are from their core competencies (look at the talent overwhelmingly represented in their org charts), the more likely long-term vendors will persist and grow here.
At risk of shilling, these are why I've personally placed bets into the likes of Phinity (the hardest verifiable domains with few domain experts), Hillclimb (the experts in the world that represented the brightest of humanity), and Build AI (building the stranglehold on legacy data for the physical data modality).
Of course, the expansion of data markets also makes data markets more attractive for M&A to external players who can now see the strategic components and core competencies much more clearly.
Giants tripping over themselves
Yet again, I feel that a venture markets perspective is invaluable for understanding where data markets are headed and why data startups act the way they do. By virtue of taking on equity capital, often from aggressive brand name VCs, you are expected to burn a certain amount and thereby grow according to that burn. This creates behavior (sometimes empire building behavior) that leads to the earlier point I mentioned on scaling quantity without necessarily matching quality but also a drive to enact business decisions without adequate market reciprocation.
Such behaviors are also justified by "our competitor will take our lunch" and "we will learn fast by failing fast." For those operating in data markets, trust with researchers is everything (evidenced by Afterquery and Mercor), and, just like other SaaS vendors, can be easily broken once and forever. Indigestion is a common trait seen in companies in data markets that scale
When I was working in growth equity, fundraising was a quality I looked for. As an intern at an unnamed growth shop, I was given something that looked like this:
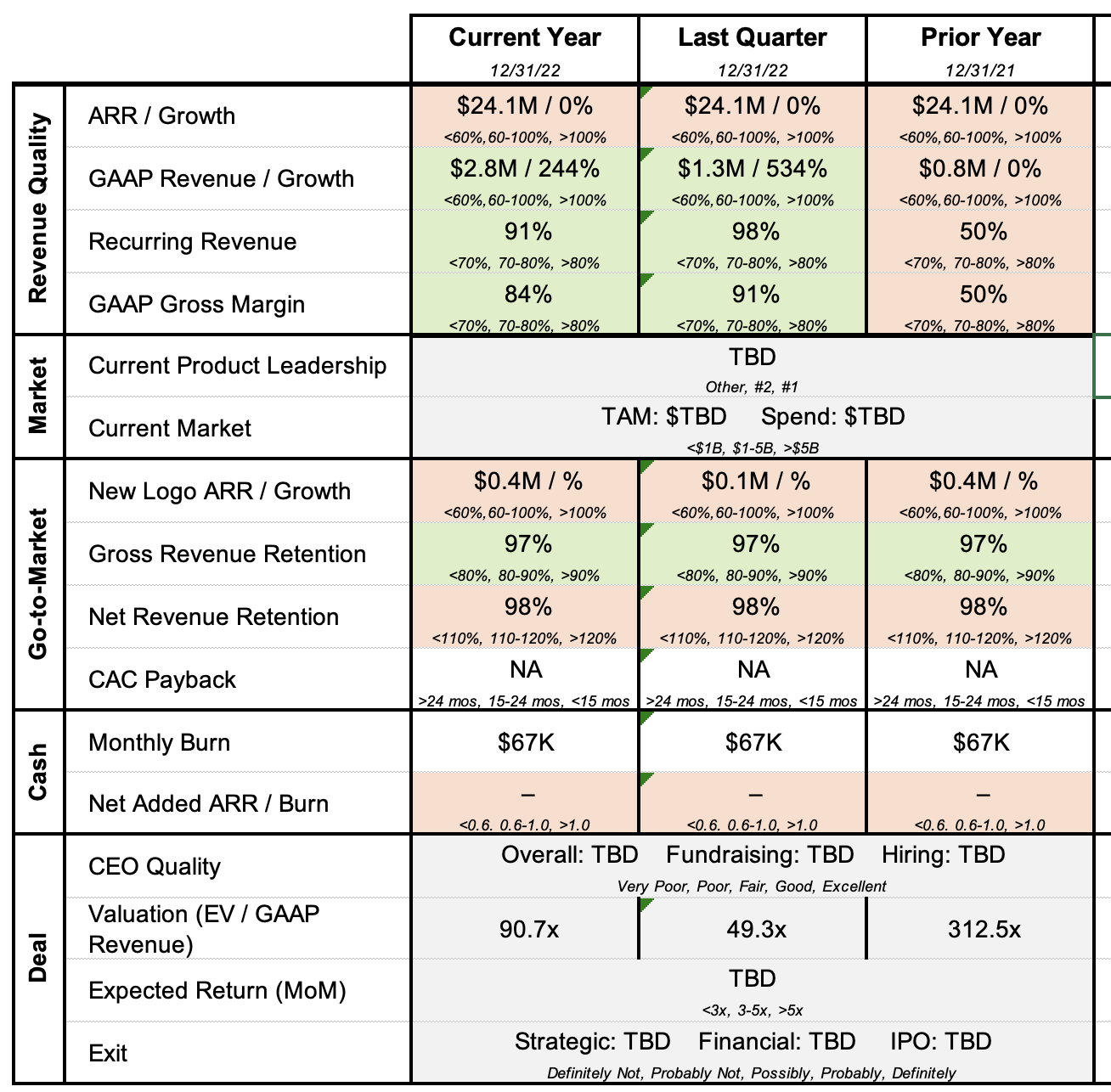
Good benchmark metrics for 2023, I guess
As private capital markets place more downstream pressure by forcing more capital downstream, fundraising becomes an increasingly important quality that comes into play earlier. That startups can build warchests at seed/A nowadays means that we should scrutinize and update the rest of the metrics on the above sheet. Does it really make sense to allow a seed startup to annualize their 3 month pilots' conversion revenue (with incredibly dubious and hard to reach conversion KPIs) if you also know they have the funding of a 2010s Series C startup?
In Victoria 3, there is an event regarding oil mortality that looks like:

Where there will be oil there will be blood
This is emblematic of what is going on in the rush for the new age commodity of data. Empire building is really bad. I've heard rumors of incredibly egregious behavior, and the smearing that some data companies commit towards former employees/contractors who spin off into their separate things. Some of this is deserved, but some is more emblematic of the worse excesses of cult-driven cultures in young founder founded startups.
Maintaining a culture that is nimble enough to adapt to new GRPOs every 6 months seamlessly is incredibly difficult. Taking on equity capital from activist investors can bequeath the typical benefits of being high profile, but presents a unique sets of pressures on scaling quantity at the cost of quality. This unique pressure set differs company by company, but the continued failure of many data giants to fail to scale quality has convinced labs that keeping human data vendors fragmented is in their best interests.
But this isn't even confined to giants. It is really easy to build a startup in this space, realize that you're getting a $1M run rate a month through an extremely intensive ops heavy motion, and relax innovation. Or innovate, just trying to increase the throughput of one of your data production methods, like automated environment creation, without thinking about your place in the data markets. If you want to build a giant, you need to be desperate to monopolize either vertically or horizontally. Already, I've heard of struggling data/rl envs startups in their A raises in the new year, who've copied early Mercor's model internally without special care for platformization and verticalization opportunities.
The right hires and the actual new labor market
If we take the factory analogy a bit further, the best hires for maturing human data companies seem to be AI-native Toyota executives. Mercor would have been better off hiring a Toyota method executive from Japan than some Uber execs if they really wanted operations streamlining expertise (barring language differences). The MBA's textbook Toyota assembly method, eerily, has extremely strong applicability to an industrially unbundled human data collection process.
Because we are biological beings with inertia, no large technological shift that abstracts away low level labor has ever not produced a large portion of luddites. This is because inherently societal constructs don't keep pace with technological innovation - centralized governments don't enforce worker up-skilling in tandem with private sector rollout. This is a source of alpha for individuals in the private markets who upskill before labor markets correct for this - as seen in what decent MLE talent can do in the Bay today.
The new labor markets that all of the RL env companies profess aren't actually new jobs like "trainers for AI models." That's just a temporary gig - how can we expect synthetically created datasets, even if by world experts, across multiple games of telephone, to hillclimb models until the very end? We will develop products to enable easier data financialization by people who will keep doing the jobs that "ai replaces" (albeit hopefully at a higher managerial level), such that they can sell their purist real world data and reasoning traces so that models increasingly replace the lowest level reasoning tasks in their workflows.
The products that enable actual new labor markets are not ones which pay people to produce net new data, but rather those that allow for seamless conversion of human feedback signals in economically valuable settings (both semantically defined and involuntary behavior) into high fidelity rewards. With increasingly minimal labeling work, the average layman can convert their most opinionated workflow into deterministic reasoning trace steps in a larger, ambiguous, task.
In pursuit of new Antikythera mechanisms
Out of all the machines on the factory lines for human data that we need today, none are more needed than the ability to translate business KPIs to evals. Especially difficult because we need to ingest a variety of things for seamless integration:
- Org Charts and Hierarchies
- Seamless integration of models and agents into workflows requires a view of how human labor is delineated between human managers in enterprises. This is exceedingly difficult because ontology is bespoke to every enterprise (being a function of human culture itself) and is even bespoke at unit levels in large chain conglomerates
- User Behavior
- PMs have long known that gaining context over what users say and what they actually do is necessary for building the best systems for model interaction. The same is true for building robust RLHF loops for models in production.
- Dynamic KPIs
- When the CEO issues an edict, how are model evals and weights updated accordingly? Right now, they require high touch human intervention from MLE teams, but we'd hope that we could dynamic KPIs that translate non-technical user intent into faster model weight updates.
- In simple words, there is no easy way for human CEOs to communicate directive changes to agentic workers without extensive translation work from internal MLE teams
This machine opens the door for anyone to convert excess enterprise data into liquidity, as it also allows traditional enterprise processes to be converted to model actionable datasets and environments faster and cheaply. What is more unclear, is how whoever controls this machine to best accrue economic gains, and how widely disseminated this machine will be.
There are smaller, sub-requisite machines such that we can refine and make available more enterprise data. These include:
- Anonymization technologies that allow more consumer companies to sell user-specific data, bypassing data privacy laws
- Higher fidelity ingestion techniques across different modalities (think voice surveys of employees via Listen Labs/Natter) such as to create evals even closer to IRL human manager feedback
- Data liquidity mechanisms and markets such that the holders of economically valuable knowledge and processes can more easily be connected to our enterprise data supply chains (segueing into my next section). These are largely dynamic financial instruments with API integrations that have context over unstructured data and economically valuable enterprise data. Kled is a blatant and most forthright attempt at this.
But perhaps the most Antikythera of mechanisms that current RLaaS and MLE-led companies are coveting today is the ability to implement robust HF collection mechanisms in enterprises such that they can get the full range of data needed for quality ML. Here, the ex-OpenAI research engineer struggles with a Luddite employee who doesn't want their job to be automated, the executive who maliciously does as little as possible to get his paycheck, and org charts that self-sabotage their data lineage over years of mismanaged culture.
The twitter-popular term as of late is "context graphs" but this is still an incredibly MLE-centric way to come up with a solution for a problem that is simply that "we don't have ways to create robust enterprise-specific evals from undying buy-in from humans" and most enterprises don't have startup level cult cultures (where every employee openly displays enough devotion to create good semantic reasoning traces for evals).
So, instead, we have to infer our reward shaping from observed behaviors.
Proposed solutions here range from simple DPO pipelines with right/wrong pairs (unsuitable once horizons start increasing beyond yes/no tasks) and Palantir-esque regular consulting sessions to extract the MLE's answers for reward model shaping from semantic human speech).
Low level reasoning is easy because most low level reasoning problems are easily verifiable. Chaining together multiple low level reasoning (aka, an enterprise workflow) becomes difficult because verification is difficult even by human standards. (This is also called democracy as humans together make joint verification decisions by consensus).
Perhaps the draconian implementation of some Antikythera mechanism to collect robust data from unwilling enterprise stakeholders lies in an exceptional executive, but perhaps we can also figure out a way to infer the majority of our reward shaping from frictionless enterprise adoption mechanisms (or maybe they should've just hired better low level employees).
What very few people are talking about today is how this simple fact guides the development of every single RLaaS and model infra company today:
- The likes of Applied Compute spend a lot more of their time doing Palantir-style consulting rather than actual RL (though model training, after all, is autonomous)
- Those that come from traditional enterprise (and also have MLE expertise) and are disillusioned by the state of its immaturity choose to build platformize and be opinionated about the most common agentic use cases today to build infra for
- Some dreamers want to "re-imagine" the ERP layer itself and make it record processes in addition to data states. While I've no doubt this will be the case in the future, whether by ASI or new software, this will not be rolled out overnight and generally not possible in the next 3 years (looking at you context graphs). There are simply too many modalities of data that we need better models for to ingest properly still (at cost).
- And many choose to ignore everything I've just said, say fuck it, lets focus on the micro, and charge 8-figure services based engagements for bespoke model training (automations for the most bespoke, but long horizon enterprise use cases) for the likes of Coinbase and Brex and call it venture scalable
The Antikythera mechanism was an object that should not have existed in its time: recovered in 1901 by Greek sponge divers from a Roman-era shipwreck off the island of Antikythera, it emerged from a historical period otherwise defined by manual navigation, oral astronomical tradition, and pre-industrial craftsmanship. Its sophistication was not remarkable merely because it could predict eclipses or model planetary cycles, but because it embodied an entire system of abstraction, decomposition, and operationalization centuries before the institutional machinery existed to reproduce, iterate on, or even fully understand it. It represented a local maximum of organizational intelligence in an era that lacked the manufacturing discipline, incentive structures, and cultural transmission required to sustain such complexity. As a result, tools capable of solving genuinely cutting-edge problems can appear, function correctly, and then be forgotten - not because they are flawed, but because the surrounding world is bottlenecked on different problems, and periodically distracted by cycles of overinvestment and bust.
I call these Antikythera mechanisms because the limiting factor, then as now, is not raw intelligence or technical capability, but the ability to translate complex systems into operational reality - an MBA-style skillset centered on organizational structure, incentives, and culture. This is the skillset taught in Harvard MBA cases when evaluating the internal processes and cultures of large enterprises like Toyota and Walmart. It is also a skillset that has been historically undervalued in Silicon Valley, where problems were, for a long time, primarily technical in nature, B2B products could be sold to other technical fluents, and software could be made broadly usable through competent UI/UX alone. For the past two decades, the dominant bottleneck was business talent that lacked sufficient technical fluency to fully exploit software-driven development. Today, as software development and MLE work become increasingly democratized, and as enterprises gain the ability to harness data and reinforcement learning at scale, that bottleneck has inverted: technical talent is now constrained less by tooling or models, and moreso by an insufficient understanding of business structure, incentives, and organizational reality.
Its a skillset also crucial to AI-enabled transformations and rollups in general, that my friend Jack Soslow articulates well:

From Jack's company, Ciridae, on the first day of 2026, on the enduring need of aligning AI app layer products with actual enterprise culture, practices, and people
And anybody who finds that particular Antikythera mechanism can build a company 100x more valuable than Palantir.
Data is semi-liquid, finally
The universe of data buyers has expanded such that those reasonably well connected and well pedigreed in SF can treat data as a semi-liquid asset. Today, I would liken the skillset needed to treat data as a liquid asset to that similar to a pawn shop - you need some skill, expertise, and some minimal volume in order to broker, but I'd posit that many in SF can reliably do this. With common infrastructure for consumer/enterprise data collection, we might even see an "eBay for data," akin to how Meta and Google act as advertising distributors, appear.
Thrive partnered with OpenAI recently with motives that confirm this, with Thrive's roll up vehicles. Its a wonder that General Catalyst's incubation strategy, as well as the venture backed roll ups strategies, haven't caught on yet (or they haven't been public about it). If you seek to build an empire by conquest, than it seems counterintuitive to ignore the oil wells beneath the ground you conquer.
A common mistake that people make when learning that data is valuable for the first time is associating data with the data commonly held in ERP systems (aka "state-based" data). They subsequently get scared and angry because state-based data is largely personal data that is subject to all sorts of privacy regulation. The most valuable form of data today is "process-representative" data as we care more about reasoning given certain states on how to determine steps in a multi-step workflow. This data doesn't care about personal names and sometimes employees tools to "read" states - it rather lives one abstraction above personal data and deals more with the processes between moving undefined amounts of data around to achieve longer tasks.
Increased liquidity results in more arbitrage opportunities. The current RLaaS market is just MLE talent arbitrage, with the founding teams who come from nice logos getting pilots easily to satisfy top level strategic direction edicts. Already, RL environment companies' common practices include buying old enterprise legacy businesses and failing YC startups in a quest for realistic data. Outlandish strategies that I've already seen (and partake in, experimentally) involve acquiring real world white collar datasets from foreign countries with even more AI knowledge asymmetry (such like buying bankruptcy filings from South Africa's SEC).
Important to note is that the RL market remains small, while the MLE implementations and data markets remain large.
As other data markets still in their pre-training phase mature, we can observe how some lessons from text/reasoning based transformers can hold and where others may falter:
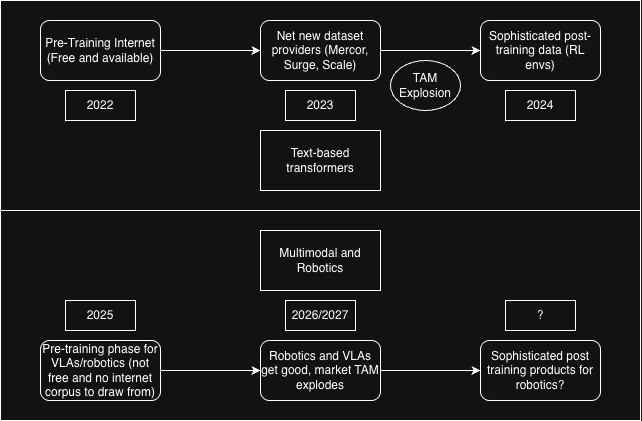
Evolution of Data Markets across different modalities
Is the TAM for multimodal data and robotics all of blue collar labor yet? We're probably many steps behind even saying that given the haphazard direction of VLAs and general purpose robotics today - we can't even agree today on whether teleop, egocentric, exocentric, or other types of data will be the most valuable for model training here today. In data modalities without the blessing of the entire internet as a free, diverse, pre-training corpus, we may need to take approaches like Eddy's (Build AI) approach to data scaling, or an alternative algorithmic approach that operates better in data scarce domains.
If you look at the history of wildly new assets becoming A) more liquid fast and B) more lucrative and useful based on widening use cases, then there can be no better examples than oil. At the start of its industrial use cases, though people had inklings of how oil could eventually become a "black gold" of sorts, only large quantities could be produced, bought, and sold because of insufficient trading liquidity (few use cases, few industries, few buyers, fewer transactions per year). As this changed, the EV for monetizing smaller amounts of this "gold rush asset" crossed the boiling point. Discovering oil in your background, even as an individual, could yield gold rush results (see the story of Columbus Marion Joiner, who discovered the largest known oil reserve in Texas in 1927 but shared a small portion of its total profits).
We see this in a sort of way with compute. In the 2010s, as mobile hardware got better, a common tarpit idea was a sort of "distributed computing" that allowed individuals to monetize the excess compute on their personal devices by porting it to a server. Compute was not liquid enough to the extent it is today (even with the advent of Bitcoin and associated proof of works, as Bitcoin introduced artificial scarcity), and so they largely failed.
Everyone and every enterprise that touches stores of data that represent real world work is privy to this EV calculation. The ones whose EV calculations turn positive first will be the ones that can:
- Convert data into model actionable formats cleanly and efficiently, likely with data pipelines
- Have information diets such that they know what the data hyperspenders want and can do price discovery efficiently
- Can fix regulatory uncertainty easily, and have the appetite to do so as well
- Gather requisite talent (by second order, financing as well) to create an ops workflow here based on all the above, whether it bogs down (Mercor) or somewhat scales well (Surge)
Though this looks like a lot of large tech companies today, the truth is that they do not pursue this path because if they possess all of the above, their empire building tendencies would rather them become a model company/app layer company (Meta, Google) rather than be a data vendor. As my skeptical investor colleagues would say to many data vendor companies we looked at before - if the data is so valuable, why sell it?
By extension, Meta and Google, when data usage becomes more sophisticated in a decade from now, can treat being a data vendor as an extremely positive cash flow business in the same way that their advertising businesses are today, and possibly finance whatever intensive CapEx tech buildout comes next.
And some individual, when they realize how to tap data frictionlessly and efficiently from the masses, will, just like Columbus Marion Joiner, capture some small wealth and be bought out by the hyperscalers of tomorrow.
Everyone is unsophisticated until they're not
Victoria 3 is a Paradox Interactive game that actually does an excellent job of simulating the industrial revolution, of which I wrote about its parallels to today's data revolution. I wrote about how Victoria 3's system of one-click production method implementation was inaccurate:

Victoria 3 production method implementation
I'll revise that claim slightly. It was inaccurate for industrial systems between roughly 1836–1936 because of communication bottlenecks, capital frictions, and slow knowledge dissemination. Today, however, it is directionally accurate in a limited but important sense: we now have the internet, global capital markets, and unreasonably efficient knowledge search and retrieval.
Knowledge dissemination today happens continuously and often unintentionally. Increasingly, people use ChatGPT and similar tools as a first resort for learning, and these systems surface cutting-edge production methods from blogs, GitHub repositories, and arXiv papers that would have taken years to diffuse in prior industrial eras. The result is that the gap between those with agency and those without compounds faster than it did historically.
As I write this on a plane back to San Francisco from an eight-day hiatus traveling through Taiwan and Shanghai, I am already inundated by the velocity of dissemination. A founder I'm corresponding with building a B2B sales tech tool has pivoted to building an open-source alternative to Tinker. Another founder building an AI app-layer company brought bare-metal H100s online after realizing this was now a viable margin strategy. An angel portfolio company scaled a theoretical architecture to near-frontier benchmark performance after reading about distillation techniques just months ago.
This is the sense in which everyone is unsophisticated until they're not. The constraint is no longer access to information, but the willingness and ability to operationalize it. The people and organizations that internalize new production methods early do not merely gain incremental advantage; they reshape the local equilibrium of their markets before others can respond. Its not that data markets will fragment, but that they must. Quality does not scale linearly with quantity, incentive structures in venture-backed organizations favor overextension, and the marginal buyer of data is increasingly sophisticated about vendor risk. Fragmentation is the durable equilibrium of an industrializing data economy.
When I visit the plethora of data and RLaaS company offices I spend the most time around today in SF, the information diet sources are well known. We still face the same qualified education sources to utilize newest production methods as in 1880, but this time the delta between those with agency and those without are even higher. In some ways, this is inhibiting growth because the founding employees that those who would found would higher can often access private capital to go do things themselves.
My vantage point as an investor and pseudo-operator allows me to see this play out repeatedly. I see large enterprises with applied MLE teams contracting post-training data vendors at the same moment those vendors believe only frontier labs are worth selling to. I see churn at incumbent data providers coincide with first windfall contracts for unknown RL environment startups. I see how cultural decay, financial mismanagement, and misaligned incentives at data vendors propagate upstream into degraded model quality. I see how "$12.8M annualized ARR" often resolves into three-month pilots with fragile conversion clauses attached to the hardest, least-validated ML problems inside enterprises.
None of this is anomalous. It is what industrialization looks like when the commodity is semi-liquid, the labor is cognitive, and the production methods evolve faster than the organizations deploying them. Everyone starts unsophisticated. The winners are simply those who define what being sophisticated actually means.